
Итак, представим, что у нас есть 2 филиала институтов, и нам нужно объединить данные по студентам в 2 таблицы. Проблема может быть только в главных ключах, то есть, если в одной таблице нумерация идет 1,2,3… и в другой… 1,2,3…, то, после соединения, если в процессе не будет ошибок, результирующая таблица будет с ключами 1,2,3,1,2,3… и, нарушится целостность.
Таким образом, чтобы выйти из этой ситуации, можно изначально проектировать таблицы с различными ключами, например, в одной таблице 1,3,5…. В другой 2,4,6…. И тогда, при объединении, мы избавимся от такой проблемы….
На данный момент, к сожалению не нашёл как сделать такой “финт” в программе workbench, потому что в разделе Options, там есть только поле Autoincrement, возле которого написано Initial Autoincrement value for the table. То есть, насколько я понимаю, это стартовое значение, а вот где настраивать шаг автоинкремента непонятно…

Итак, чтобы продолжить эксперименты с объединением таблиц, можно пойти 2-мя путями – создать 2-ю модель, из неё 2-ю физическую базу данных, в ней – аналогичную таблицу.
Либо другой путь – создадим внутри нашей первой модели дубль таблицы Students, под именем Students2, и объединим эти таблицы. Надо понимать, что для объединения таблиц – у нас должно совпадать число столбцов и тип данных… Поэтому для начала объединим идентичные таблицы, заодно посмотрим ситуацию с ключами, поскольку в той и другой таблице – ключи идентичные…
Итак, Copy “Students” Paste “Students”, и у нас возник дубль таблицы, но, если мы зайдем на вкладку Inserts этой таблицы, тогда выясним, что она пуста… То есть, скопировались только поля таблицы, но не записи…
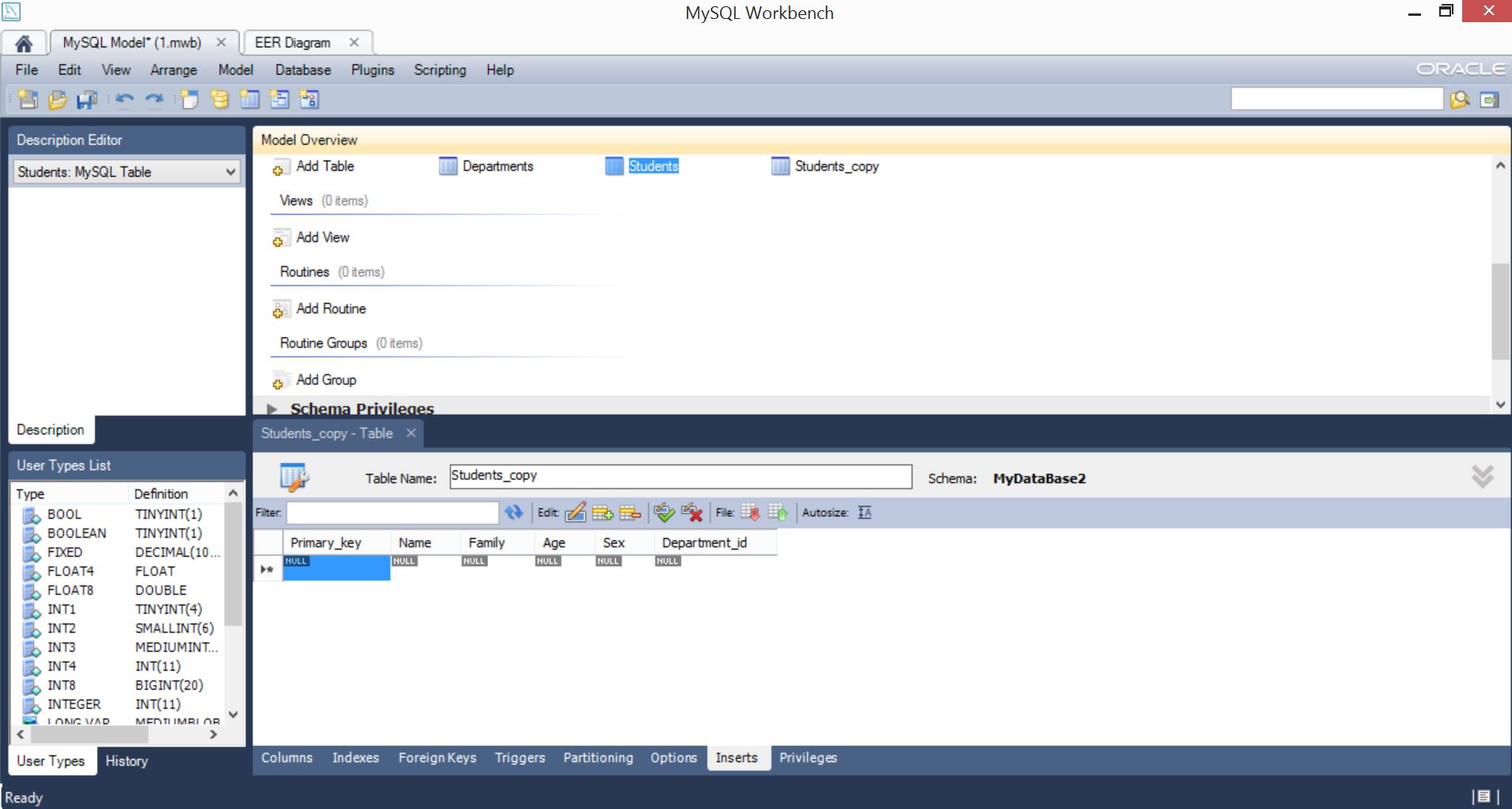
Тут можно поступить разными способами – нажать правой кнопкой мыши на “Students” и выбрать copy inserts to clipboard, при этом в буфер скопируется скрипт, который потом можно будет выполнить. Но, поскольку, мы учимся, пойдем более простым путём – забьем “ручками” новые значения, таким образом, чтобы при слиянии их потом можно было отличить.
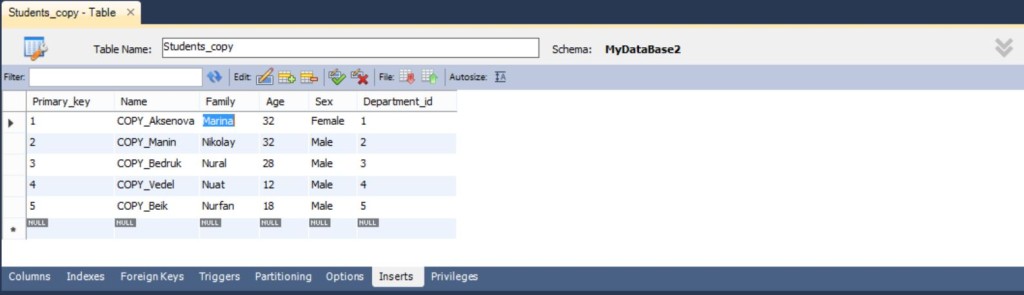
Итак, я забил произвольные данные и проставил ключ от 1 до 5 с шагом в 1, то есть пересечение с таблицей Students есть. Посмотрим как отреагирует система на слияние таблиц. Чтобы отличать эти записи, среди всех после объединения, я добавил слово COPY_ перед именем. Итак, выполним извлечем скрипт и выполним его на сервере, для того, чтобы добавить новую таблицу в физическую базу данных.
В процессе выполнения скрипта, у меня появилась ошибка errno 121, для того, чтобы временно избавиться от этой ошибки – я удалил описание внешнего ключа у таблицы Students2 и скрипт выполнился. На данном этапе важно посмотреть как объединяются таблицы, со связями между таблицами будем работать чуть позже.
Итак, для того, чтобы проверить наличие таблицы Students2, создадим в Delphi новый проект, на форму поместим SQLConnection, SimpleDataSet, DataSource…
Во View Data Explorer создайте новое подключение, либо отредактируйте старое таким образом, чтобы в клиенте Delphi вы могли видеть таблицу Students2 (о том, как настраивать такое подключение можно прочитать в статье).
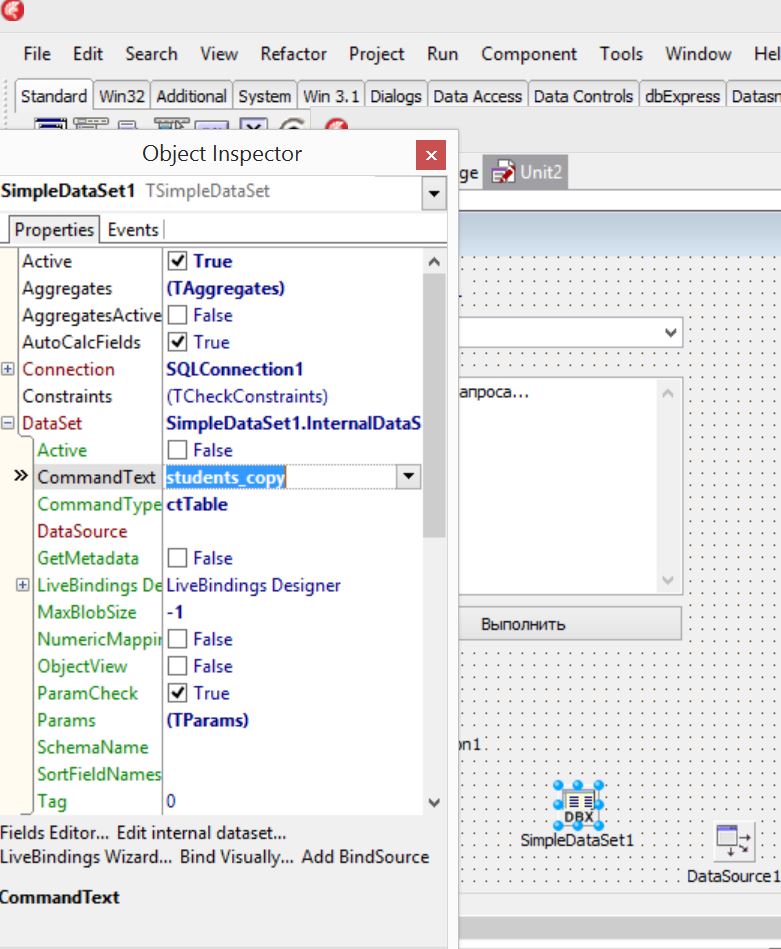
Проверить это очень просто – в компоненте Simple Data Set, в объектном инспекторе – выберите в свойстве CommandType – ctTable. А в CommandText – таблицу Students2, если всё правильно сделали – она будет отображаться в выпадающем списке CommandText.
Теперь нам нужно на форме разместить 2 таблицы – Students и Students2 и где-то отображать 3-ю – результирующую таблицу… Я немного усовершенствовал форму и сделал таким образом…
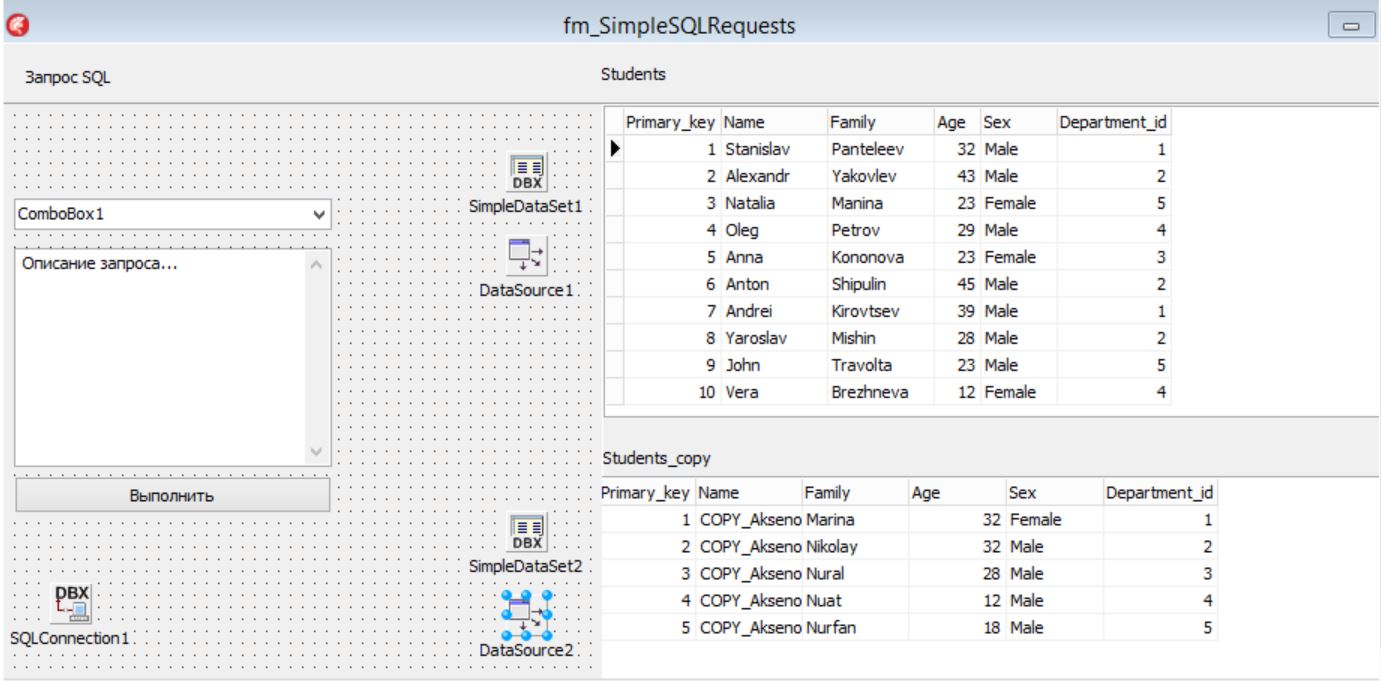
А после компиляции это выглядит так…
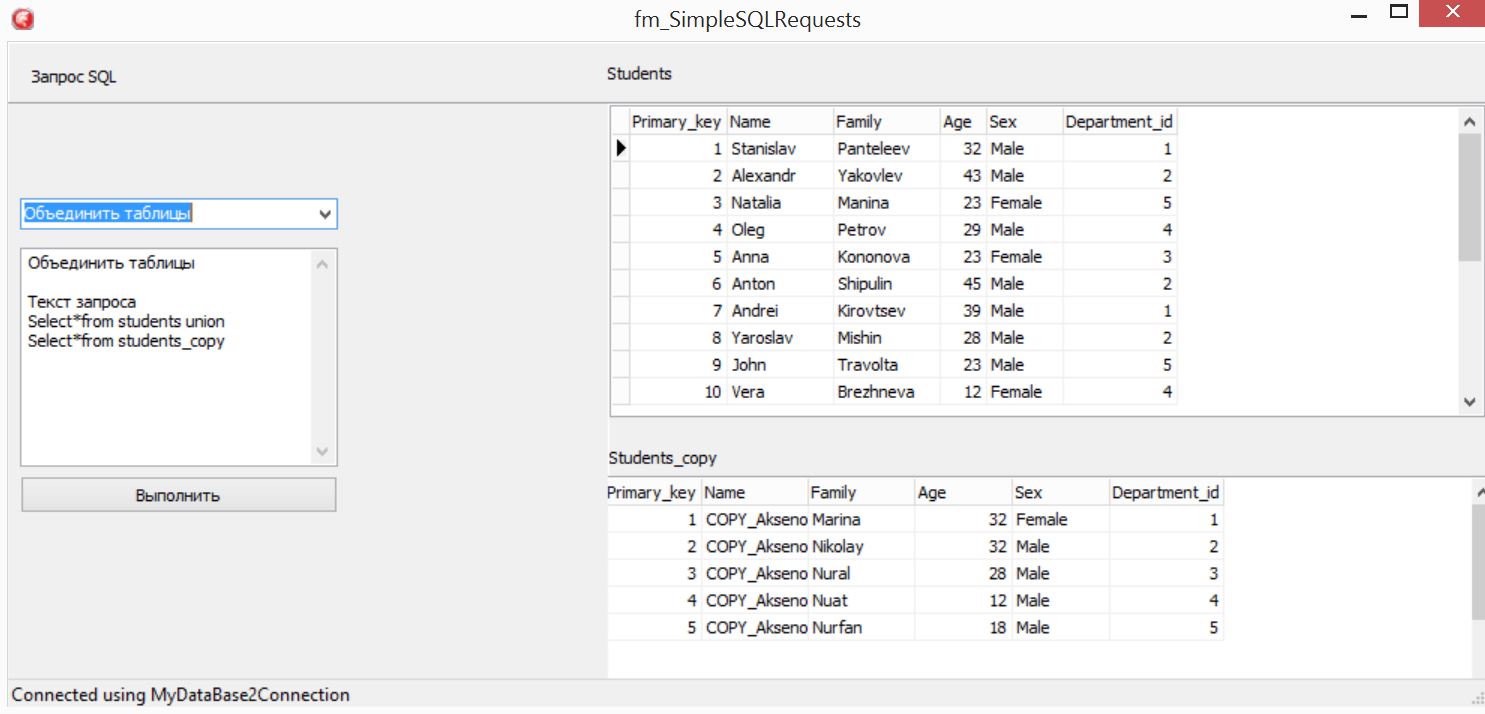
В клиенте “зашит” единственный запрос Select*from students union Select*from students_copy
После нажатия на кнопку ВЫПОЛНИТЬ получаем результирующую таблицу

Обратите внимание на ключ… Система никоим образом не проконтроллировала, чтобы ключ в результирующей таблице был уникальным. После 10-й записи, у нас все начинается с 1-й записи, а это грозит потенциальными проблемами, потому что потеряна уникальность.
То есть, если бы мы, например пытались сохранить полученную таблицу в базу данных, то нарушили бы уникальность записей. То есть, если такое объединение необходимо – нужно ещё при проектировании БД позаботиться о том, чтобы ключи никогда не персекались, один из способов – делить на четные и нечетные ключи (подробнее в самом начале статьи).
Повторяющиеся записи
Итак, повторяющиеся записи по умолчанию исключаются, но если их нужно показать, напишите UNION ALL. Проведем, эксперимент. Внесем повторяющиеся строки, с помощью программы Workbench
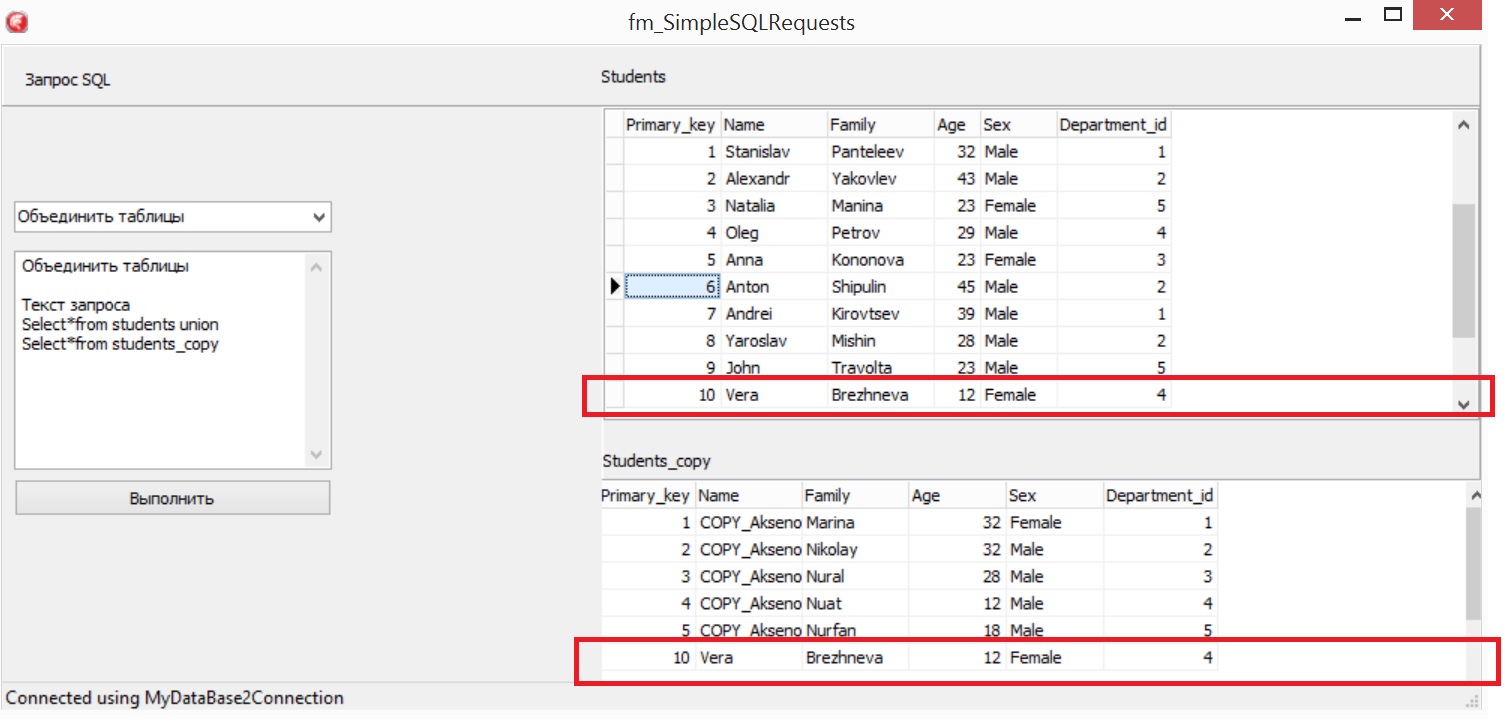
Произведем SQL запрос Select*from students union Select*from students_copy
Получим результат без дублирующей строки
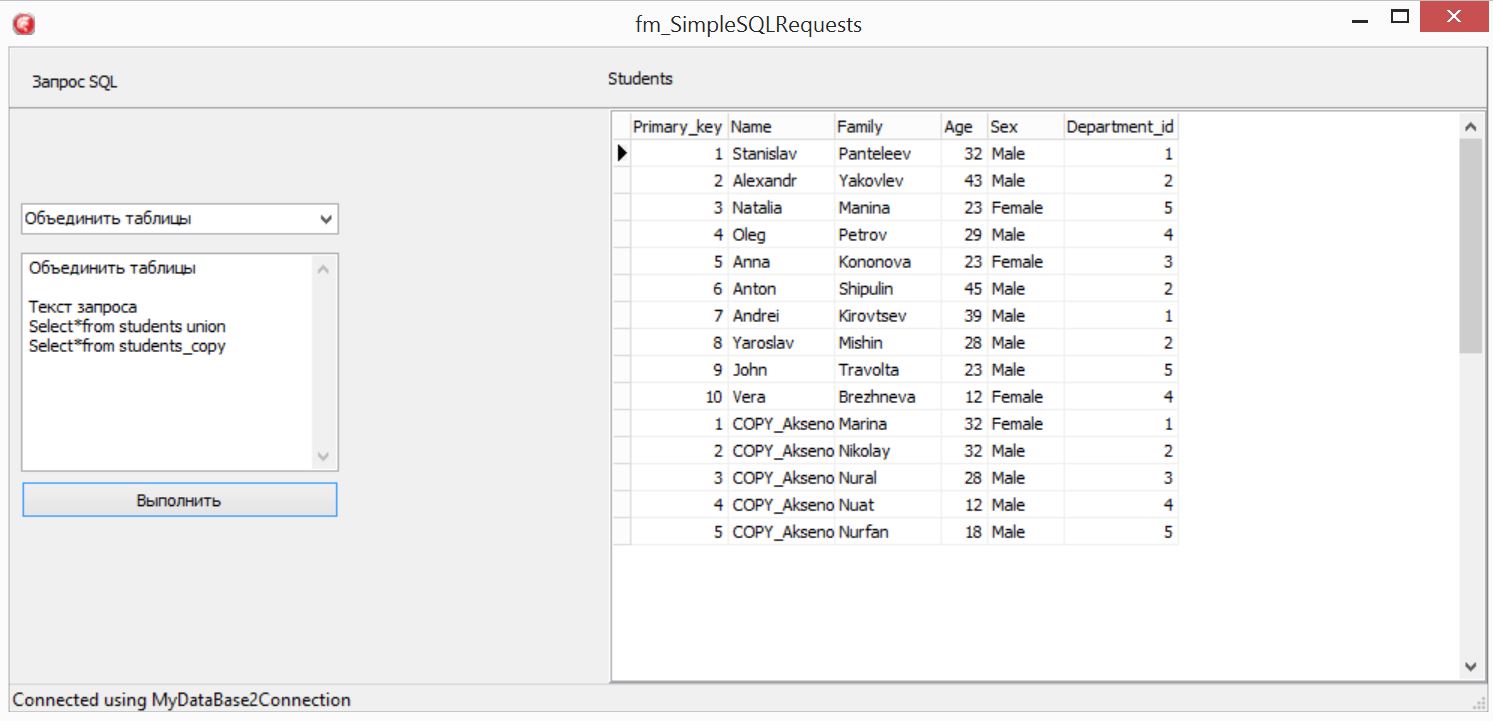
Теперь добавим в операторе слово ALL после UNION
Select*from students union all Select*from students_copy
Обратите внимание, теперь результат с дублирующей строкой…

На этом данный пост про UNION заканчиваю.
[block id=”mysql-first-steps”]