Данная статья посвящена проектированию БД. Основана на книге Д. Осипова “Базы данных и Delphi” и некотором личном опыте. В качестве инструмента БД я буду использовать программу MySQL Workbench 6.3 CE.
Теория
Согласно Дмитрию Осипову при проектировании БД мы можем использовать как минимум 2 подхода.
Первый – модель ER или по другому сущность-связь.
И второй подход – нормализация.
Модель сущность-связь (ER модель Питера Чена)
Алгорим проектирования БД в псевдокоде можно изобразить, например так
–Выделить все сущности, подлежащие хранению в БД (отделы, сотрудники, заказы)
–Выявить атрибуты (у отделов – название, у сотрудников – имя, фамилия, зарплата, у заказов – имя, количество)
–Выявить взаимосвязи между сущностями – отсутствие, один к одному (1:1), один ко многим (1:M), многие ко многим (M:N). Связь один ко многим это когда в одном отделе работает несколько сотрудников, у одного поставщика несколько контрактов и так далее).
–Разделить сущности на сильные (независимые) и слабые (зависимые) – если есть взаимосвязь и одна сущность зависит от другой, то говорят, что зависимая сущность – слабая, независимая сильная. Пример – отделы и сотрудники.
–Полученную схему отобразить в диаграммах MySQL Workbench и сделать ForwardEngeneering для создания реальной физической базы данных.
Нотации ER моделей
-Нотация Питера Чена
-Нотация Crow’s foot (“Воронья лапка”)
Нотация Питера Чена
Что касается нотации Питера Чена (схематического изображения), то она может выглядеть так…
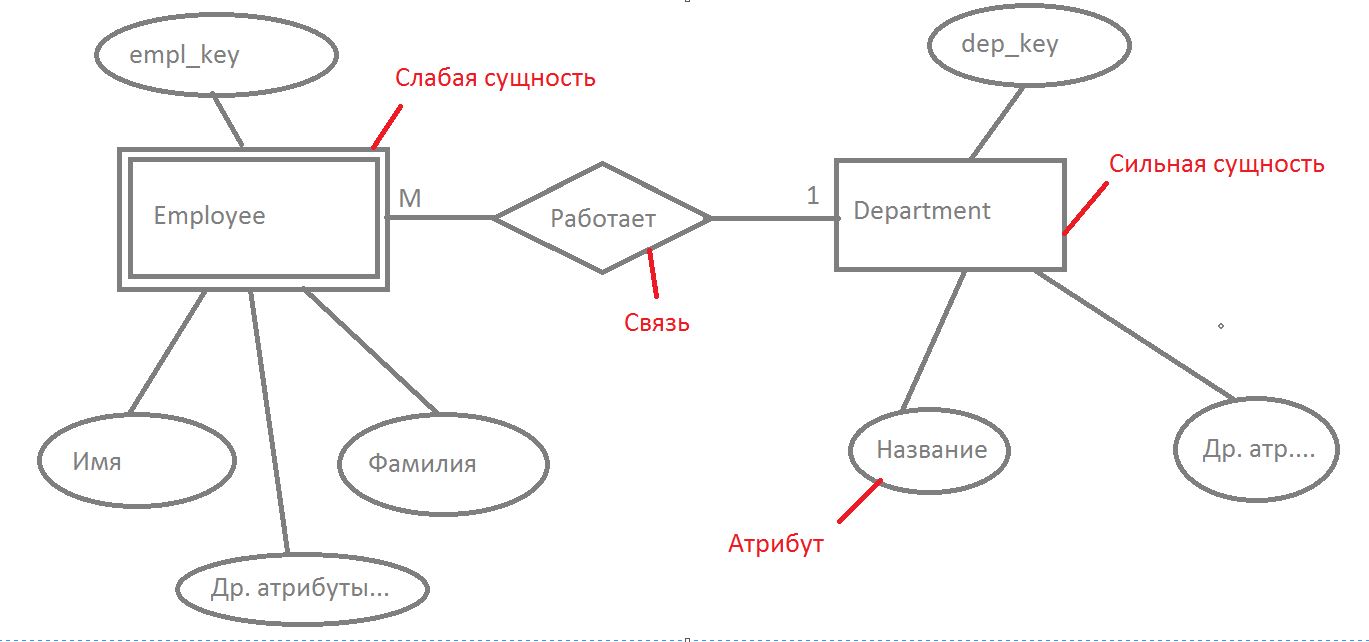
Вот принятые обозначения в нотации Питера Чена
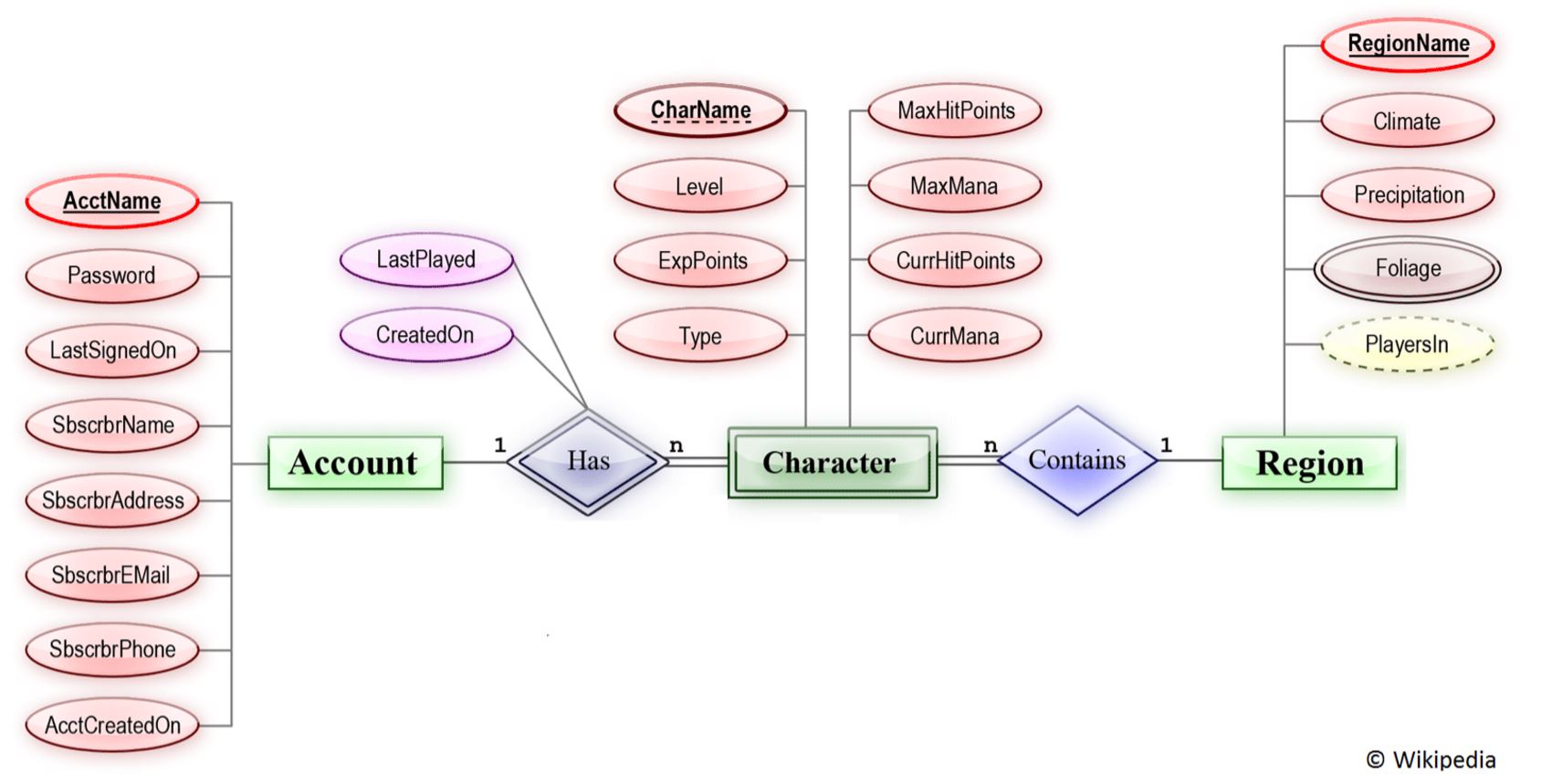
Более сложный пример мог бы выглядеть так. Пример из английской Википедии
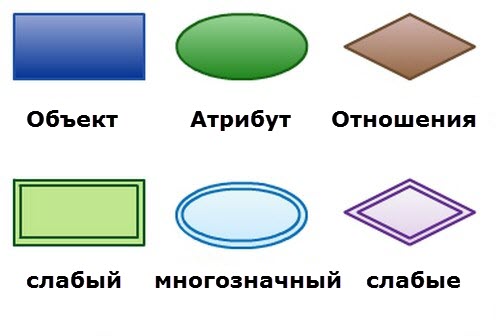{kind=link}
Нотация Gordon Everest (Гордона Эверста). Под назаванием Crow’s Foot или Fork (вилка).
Самый простой пример мог бы выглядеть так. Как видите справа у нас “воронья лапка”, означающая связь один ко многим. Один артист может спеть несколько песен. Этот пример также из английской Википедии, который есть почти во всех русских блогах на эту тему 🙂

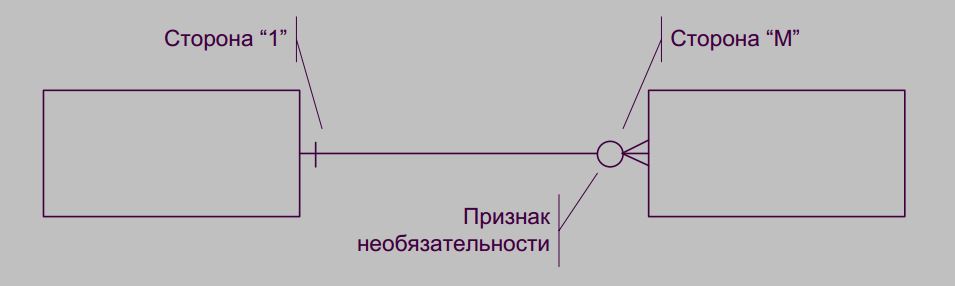
А вот пример из книги Дмитрия Осипова. Одна вертикальная черта означает “один”, воронья лапка справа “ко многим”.
Нормализация базы данных
В книге Д.Осипова говорится о 5 нормальных формах, для практической работы, на мой взгляд, достаточно четырех
1NF – атомарность или 1 поле 1 значение.
2NF – каждой таблице свой уникальный ключ.
3NF – 1 сущность 1 таблица (моя интерпретация)
4NF – каждую связь M:N (многие ко многим) разбить на многие к одному.
В своей книге Дмитрий приводит такой пример, берет вот такую таблицу и последовательно приводит её к 4 нормальной форме.
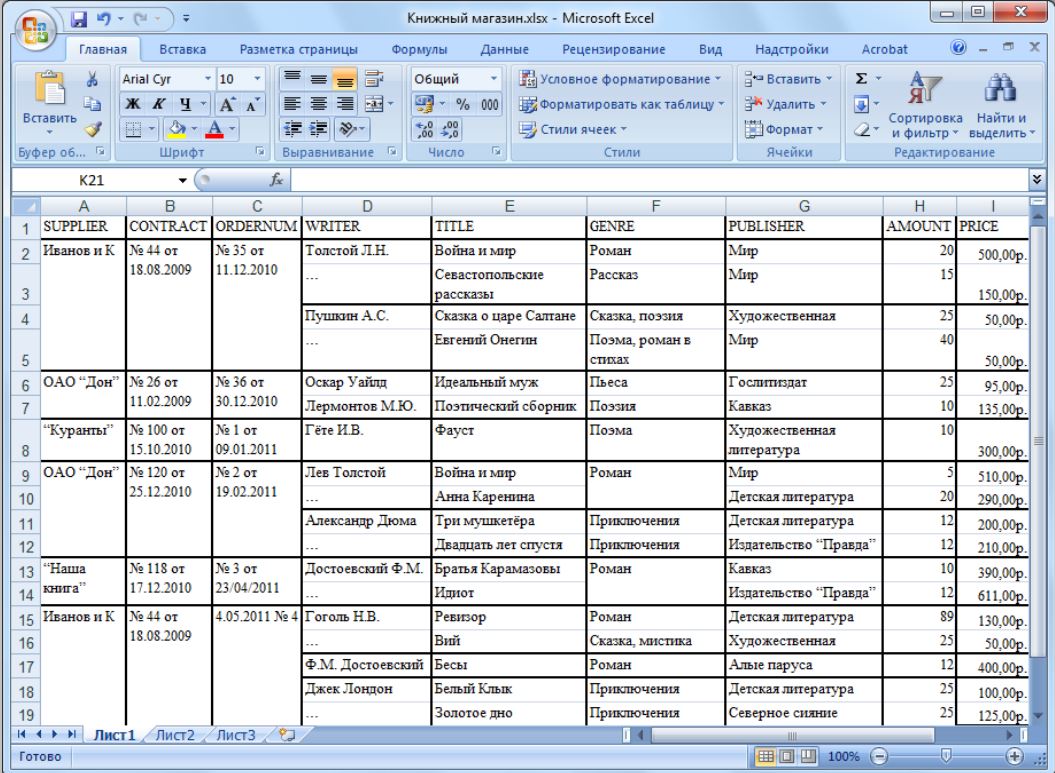
Как видно таблица – “плохая” в качестве БД, в одном поле несколько значений, уникального ключа нет, да и вообще все данные, все сущности в одной таблице, есть связи многие ко многим (авторы и жанры, и так далее). В общем, ни одной нормальной формы не соблюдено.
Повторим за Дмитрием вкратце его шаги
Приведение к 1NF – одно поле одно значение
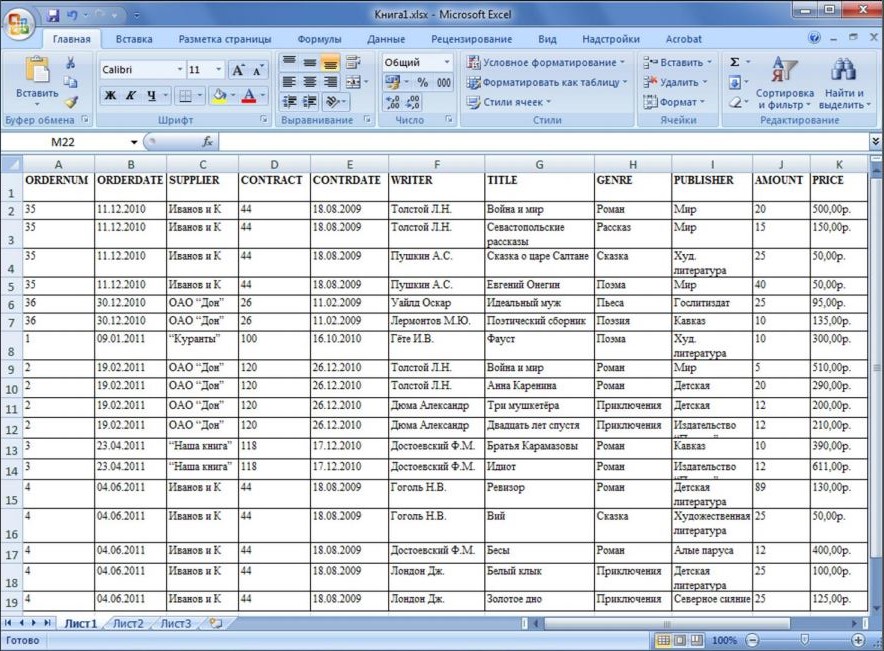
Приведение ко 2NF – прописывание уникального ключа таблице. На рисунке ниже указаны ключ и поля таблицы.

Приведение к 3NF – разбиение на отдельные, независимые таблицы. Как видно из рисунка выше – все поля у нас в одной таблице, какие-то поля являются атрибутами для других, если смотреть при помощи модели Питера Чена. С точки зрения пользователя БД это очень, очень неудобно. На 3 шаге сделаем следующее – разобьем 1 большую таблицу на несколько таблиц, соответствующих сущностям и свяжем их. Атрибуты сгруппируем по сущностям. Каждой таблице пропишем свой уникальный ключ. В результате, по книге Дмитрия Осипова, у нас получится следующее.
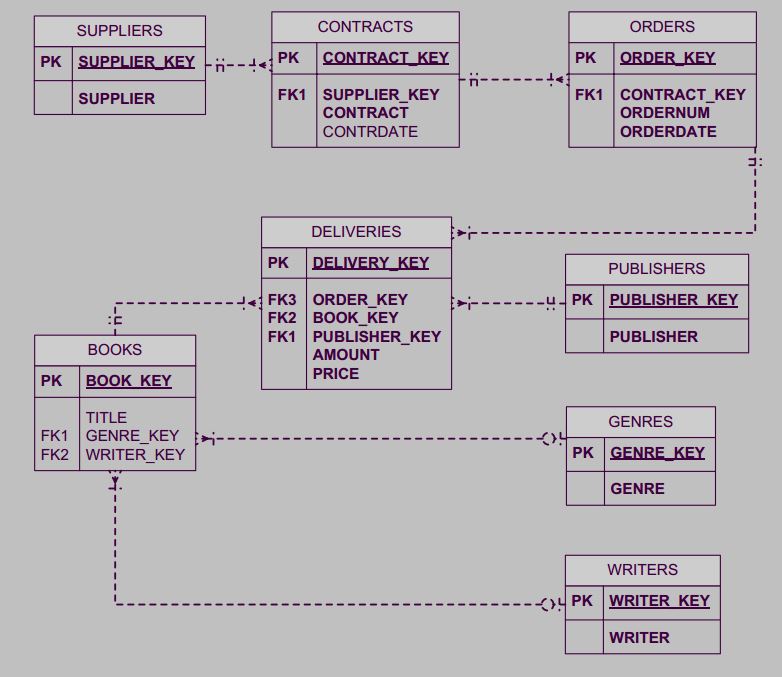
4NF – разбить каждую зависимость многие ко многим на 2 зависимости 1 ко многим. Это можно сделать введя искусственную коммутационную таблицу.
В нашем случае
-1 автор может написать несколько книг. И также можно сказать – несколько авторов могли написать 1 книгу. Поэтому вводим тип сущности WRITERS_BOOKS
-В 1 жанре может быть несколько книг. 1 книга может быть написана в нескольких жанрах. Вводим GENRES_BOOKS
В принципе этот ряд можно было бы и продолжить
-1 поставщик может иметь несколько контрактов. В 1 контракте может быть несколько поставщиков. Но тут наверное всё зависит от реальной задачи и ситуации. Нельзя угодить на все случаи жизни. А, конечно хочется)))
Но остановимся на том, что написано в книге Дмитрия. Для понимания, думаю, этого достаточно.
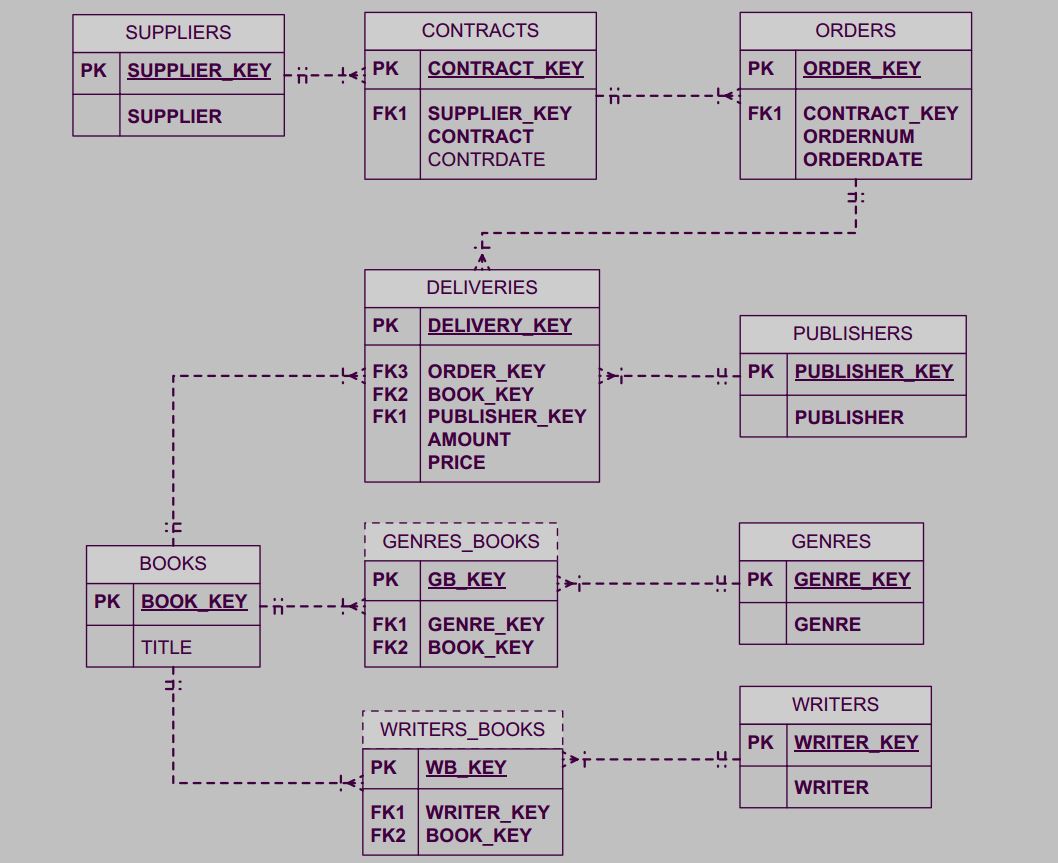
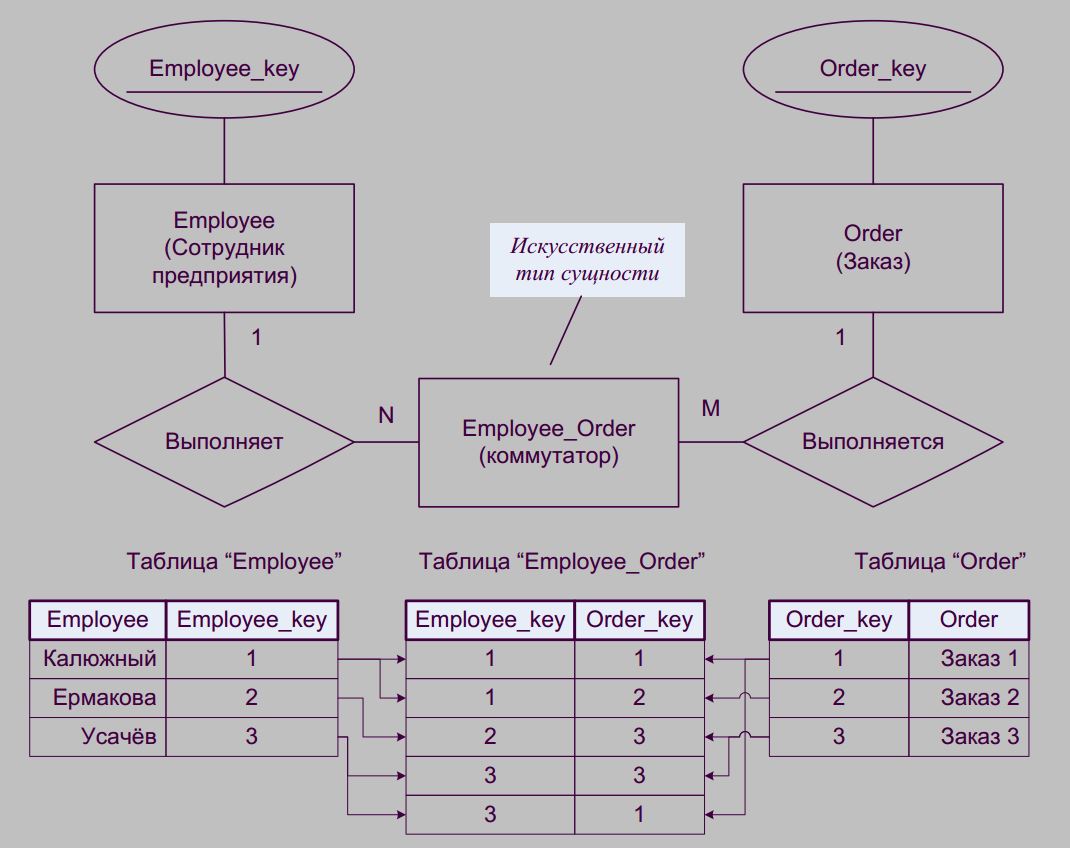
Как разбить связь многие ко многие (M:N) на 2 связи один ко многим (1:M) ?
Пример из жизни – разные сотрудники выполняют разные заказы. Дмитрий в своей книге делает вот так, что вполне логично.
Практика
Итак, попробуем решить ту же задачу самостоятельно, используя все накопленные знания. Для начала – поймем, что у нас на входе и что требуется получить на выходе.
На входе
В приведенном к 1NF виде
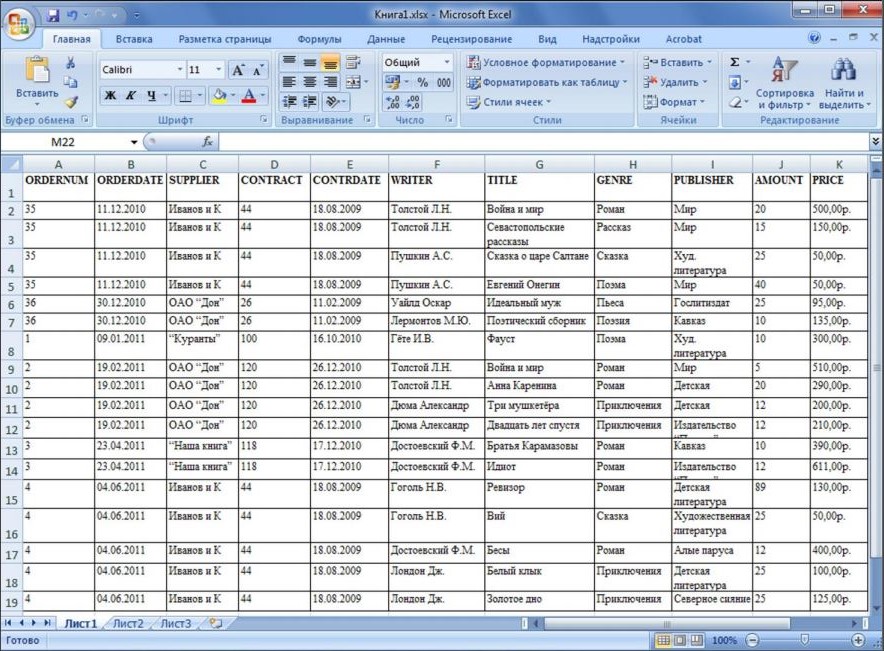
На выходе
Готовая реляционная БД MySQL, соответствующая 4 нормальным формам.
Рисуем ER диаграмму
Идём по алгоритму, описанному выше, позволю себе его напомнить
Алгорим проектирования БД в псевдокоде можно изобразить, например так
–Выделить все сущности, подлежащие хранению в БД (отделы, сотрудники, заказы)
–Выявить атрибуты (у отделов – название, у сотрудников – имя, фамилия, зарплата, у заказов – имя, количество)
–Выявить взаимосвязи между сущностями – отсутствие, один к одному (1:1), один ко многим (1:M), многие ко многим (M:N). Связь один ко многим это когда в одном отделе работает несколько сотрудников, у одного поставщика несколько контрактов и так далее).
–Разделить сущности на сильные (независимые) и слабые (зависимые) – если есть взаимосвязь и одна сущность зависит от другой, то говорят, что зависимая сущность – слабая, независимая сильная. Пример – отделы и сотрудники.
–Полученную схему отобразить в диаграммах MySQL Workbench и сделать ForwardEngeneering для создания реальной физической базы данных.
В реальной ситуации о полях таблицы (атрибутах сущностей) мы будем догадываться, например, у человека есть руки, у клиентов есть заказы, у складов есть товары и так далее, у книжного магазина есть книги, продавцы, клиенты, поставщики, филиалы, да что угодно! Список это можно перечислять до бесконечности!!!
Важно при проектировании БД выделять те атрибуты, которые непосредственно относятся к решению задачи в техническом задании иначе из проектирования БД можно вообще не вылезти)))
В нашем учебном случае – все немного проще и наш список атрибутов мы можем составить из тех атрибутов, которые даны в таблице. Но это не отменяет первого этапа – поиска сущностей. Итак, поехали.
1 и 2 Этап – поиск сущностей и атрибутов
Cущности (в скобках атрибуты)
1. Supplier
2. Contracts (ContrDate)
3. Order (OrderDate)
4. Writer
5. Book (Titile) // <<Этой сущности не было в таблице, мы увидели её и создали
6. Genre
7. Publisher
8. Deliveries (Amount, Price) // <<Этой сущности не было в таблице, мы увидели её и создали
Как отделить сущность от атрибута?
Верный знак – связь 1:1. Например, у контракта может быть только одна дата. У заказов – аналогично. У книг – только одно название. У поставок поставщиков – только одно количество поставок на конкретную дату и также при поставке – только одна цена.
В общем, логика прослеживается.
Сущность – Атрибут имеет взаимосвязь 1:1 в общем случае
Сущность – Сущность имеет взаимосвязь 1:M или M:N в общем случае
3 и 4 этап – установка взаимосвязей
Здесь можно, конечно как угодно действовать, рисовать на бумаге, рисовать в программах для интеллект-карт, но мне кажется лучше всего воспользоваться готовым софтом для ER-моделирования. Можно 1000 раз переставлять сущности, менять взаимосвязи. Итак, откроем MySQL WorkBench.
File >NewModel >AddDiagram
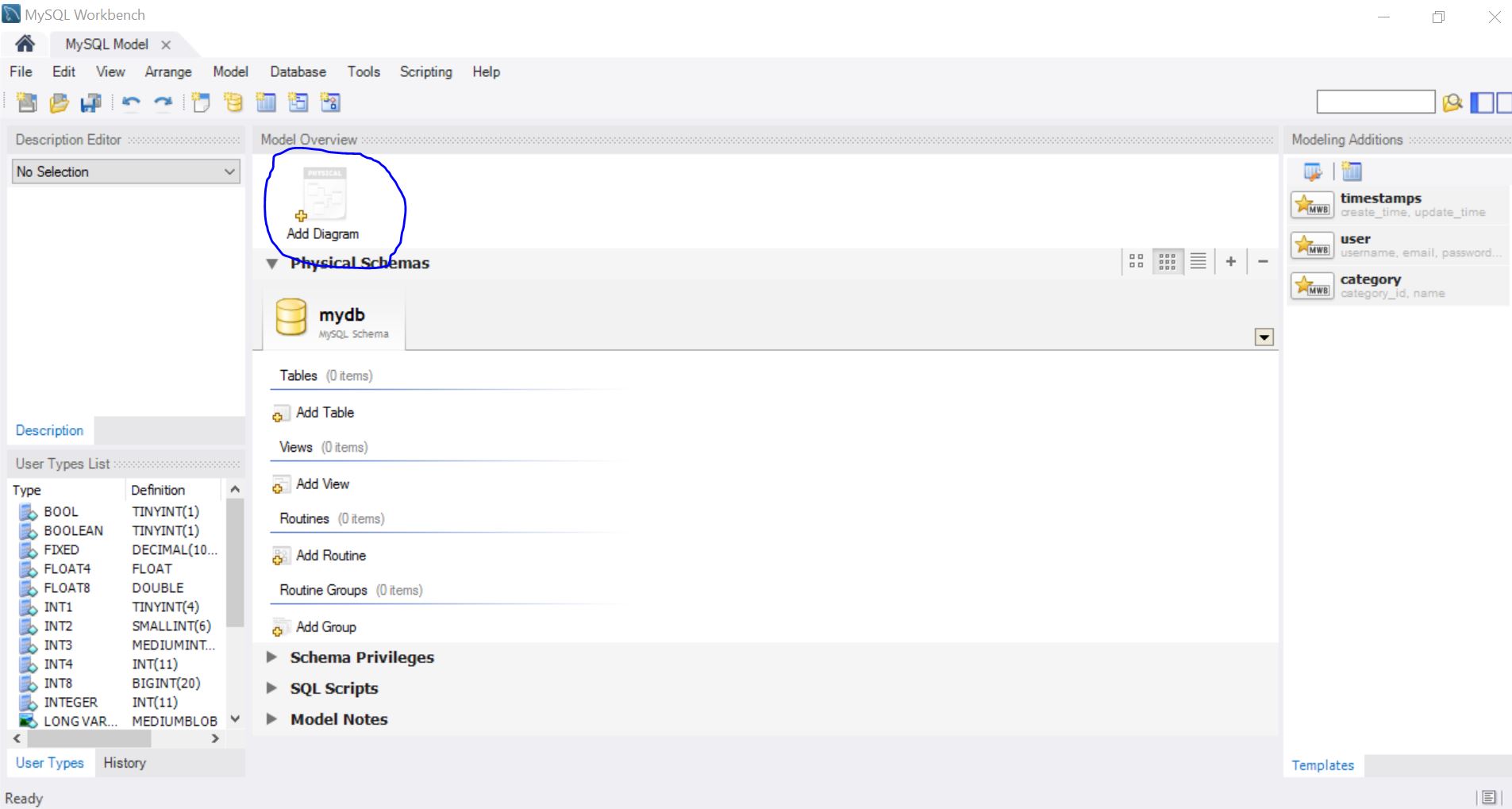
2 раза кликаем по AddDiagram. И перед нами открывается поле для действий.
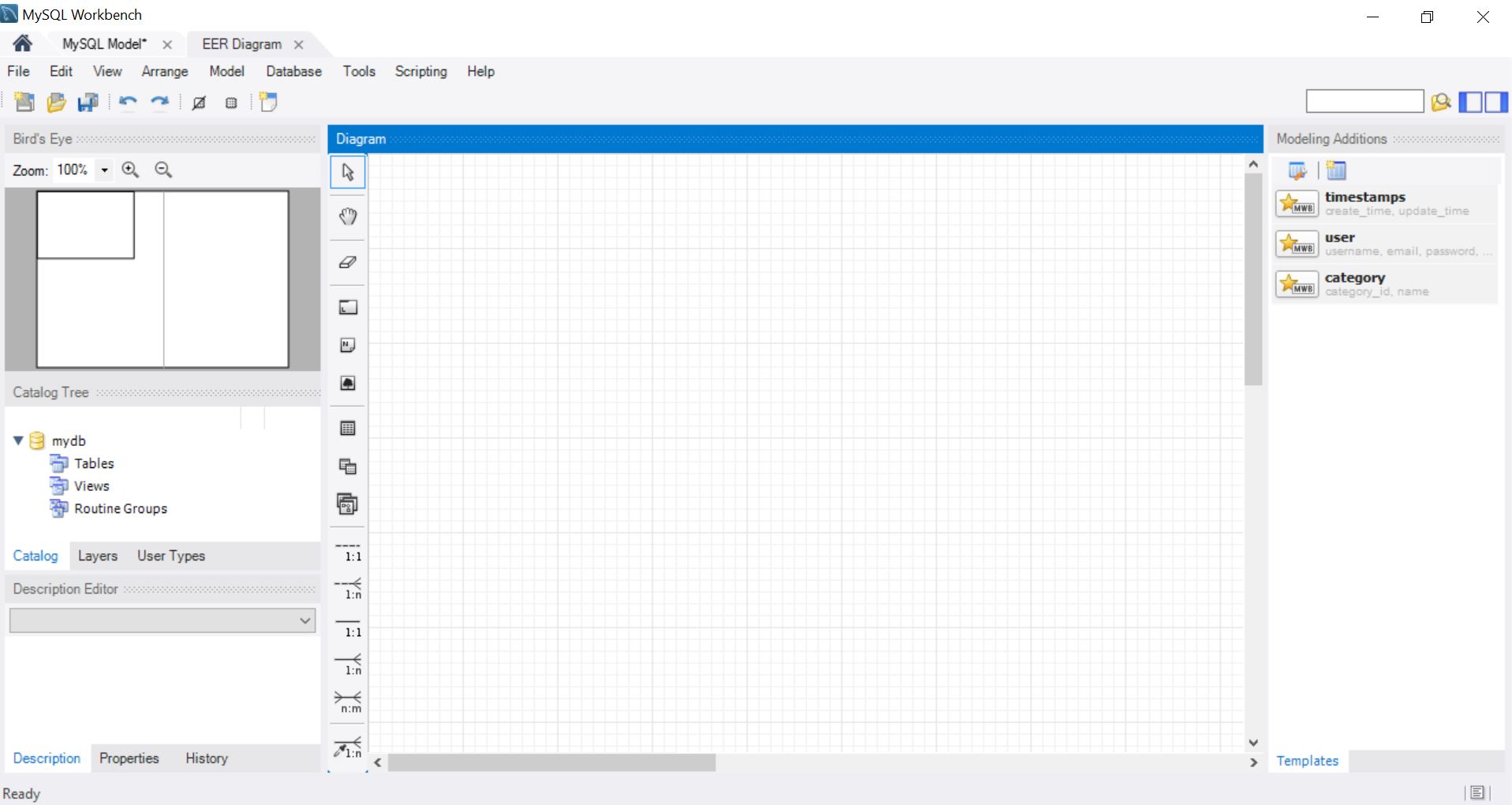
Начинаем заполнять. Сначала добавим все сущности с атрибутами. А потом установим взаимосвязи.
Как добавить хотя бы 1 таблицу и заполнить её?
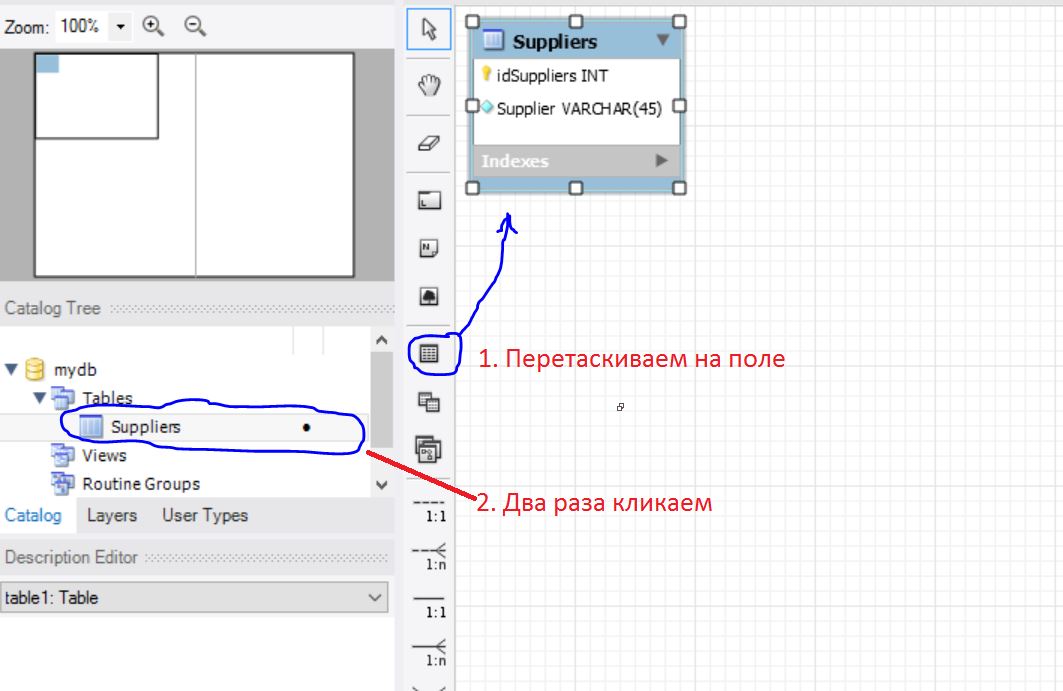
Заполняем таблицу так как нам надо…
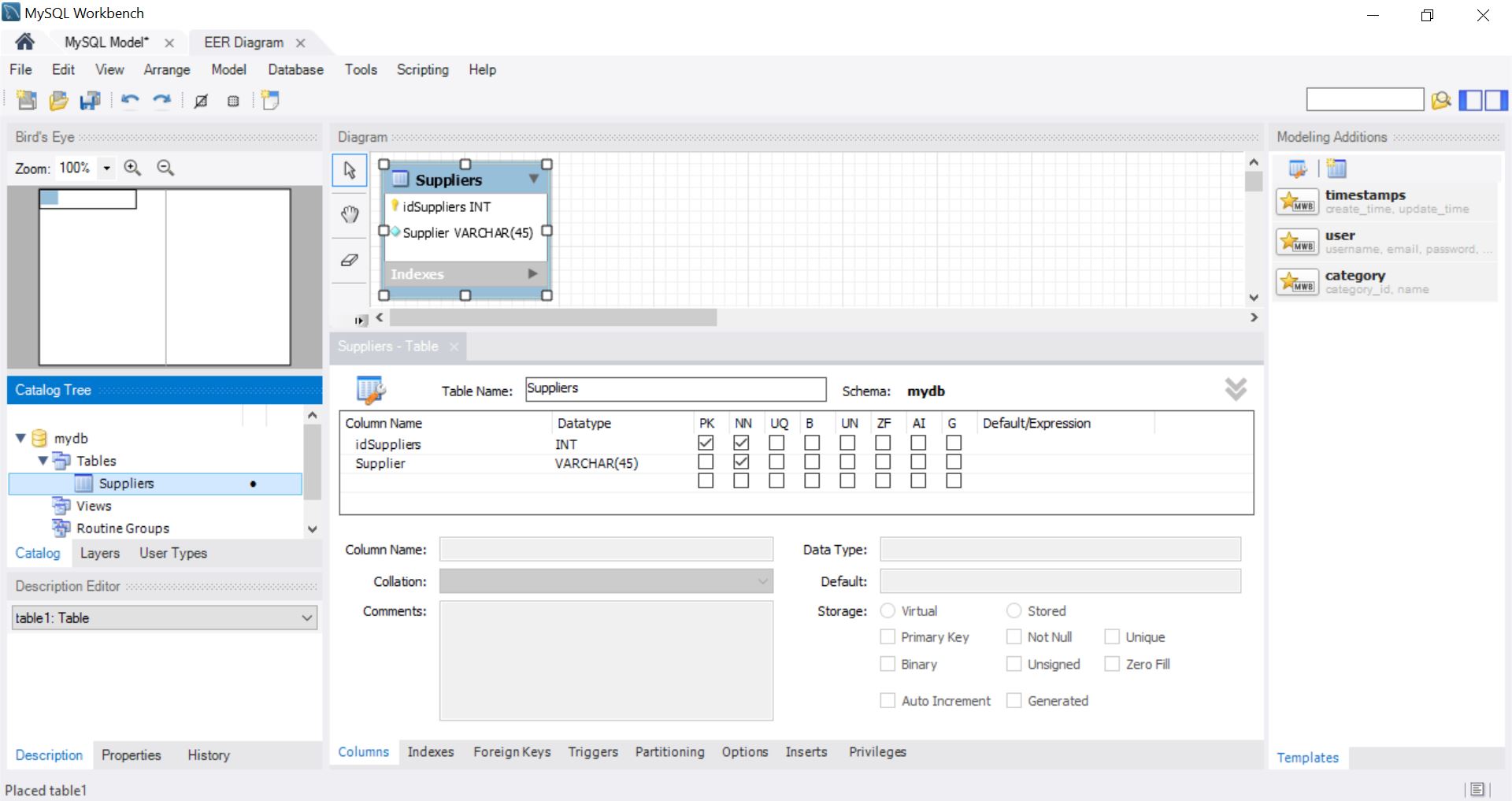
Создадим таким образом все таблицы, которые нам нужны. Всего 8 таблиц как и заказывали.
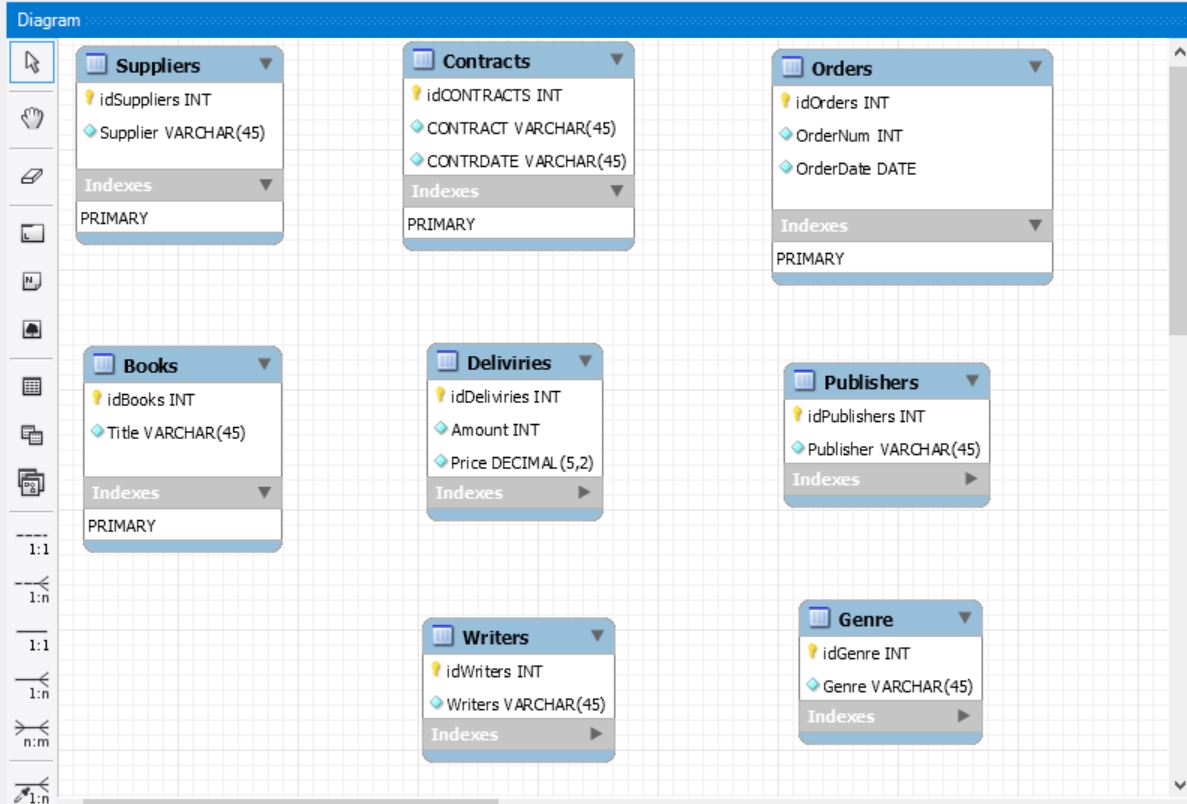
Перед тем как мы будем налаживать взаимосвязи, разберемся в следующем.
В чем разница между identifying and non-identifying relationships?
Теперь, собственно попробуем наладить взаимосвязи! Но прежде, разберемся с пунктирными и непунктирными линиями во взаимосвязях.
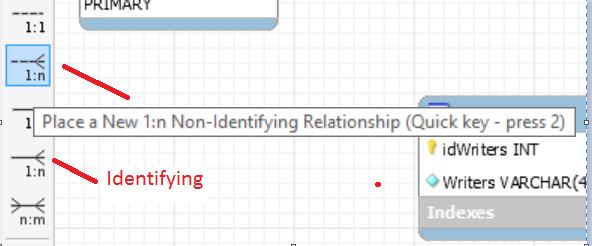
Классные объяснения на английском находятся здесь. Больше всего мне понравилось вот это объяснение
A book belongs to an owner, and an owner can own multiple books. But the book can exist also without the owner and it can change the owner. The relationship between a book and an owner is a non-identifying relationship.
A book however is written by an author, and the author could have written multiple books. But the book needs to be written by an author it cannot exist without an author. Therefore the relationship between the book and the author is an identifying relationship.
Если книга может существовать без владельца, а она может, тогда non-identifying relationship
Если книга не может существовать без автора,а она не может, тогда identifying relationship
Технически это отражается следующим образом
identifying relationship:
|
1 2 3 4 5 6 7 8 9 10 |
Parent ------ ID (PK) Name Child ----- ID (PK) ParentID (PK, FK to Parent.ID) -- notice PK Name |
non-identifying relationship:
|
1 2 3 4 5 6 7 8 9 10 |
Parent ------ ID (PK) Name Child ----- ID (PK) ParentID (FK to Parent.ID) -- notice no PK Name |
То есть, в случае identifying в ключ ребенка встроен ключ родителя. А в случае non-identifying, в ключе ребенка нет ключа родителя.
Строим взаимосвязи
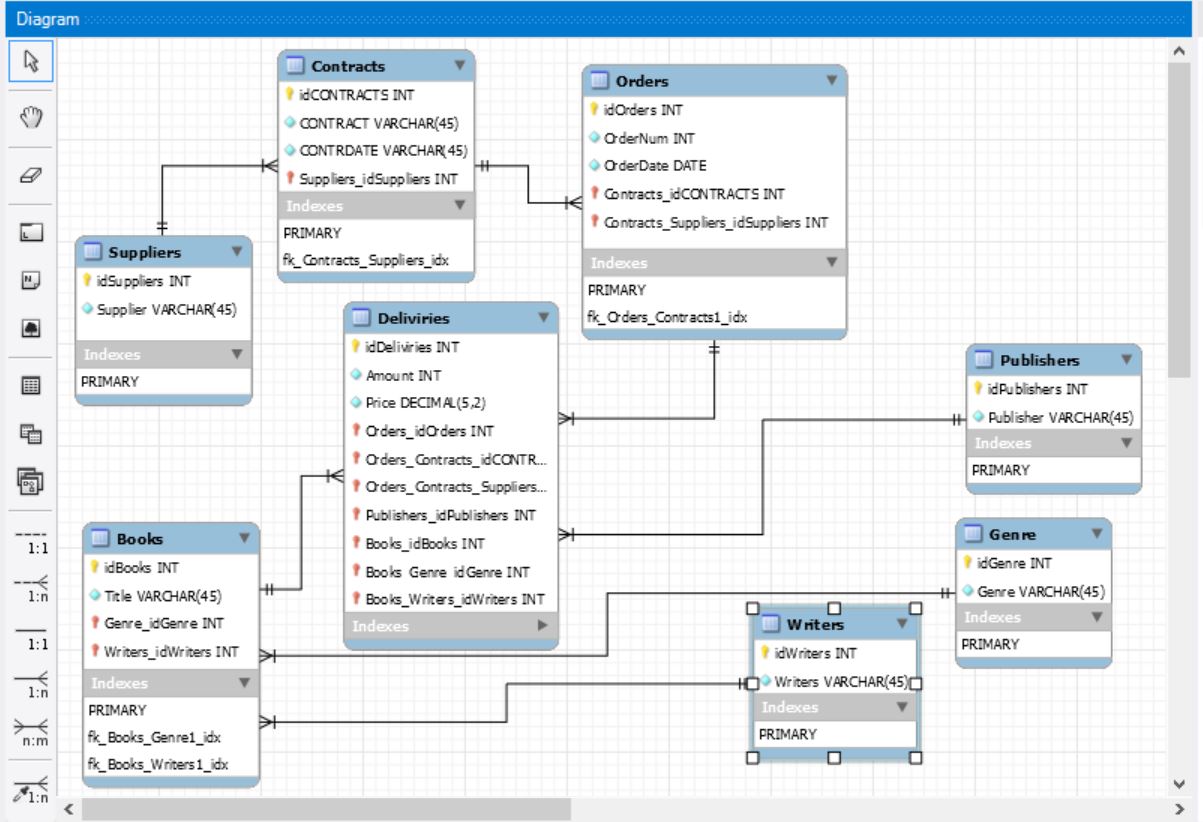
Последний штрих – разрушим связи многие ко многим
В нашем случае
-1 автор может написать несколько книг. И также можно сказать – несколько авторов могли написать 1 книгу. Поэтому вводим тип сущности WRITERS_BOOKS
-В 1 жанре может быть несколько книг. 1 книга может быть написана в нескольких жанрах. Вводим GENRES_BOOKS
Технически это просто
-удаляем старые взаимосвязи
-Теперь выбираем на палитре инструментов связь n:m, соединям наши таблицы и получаем следующее – 2 промежуточные таблицы.
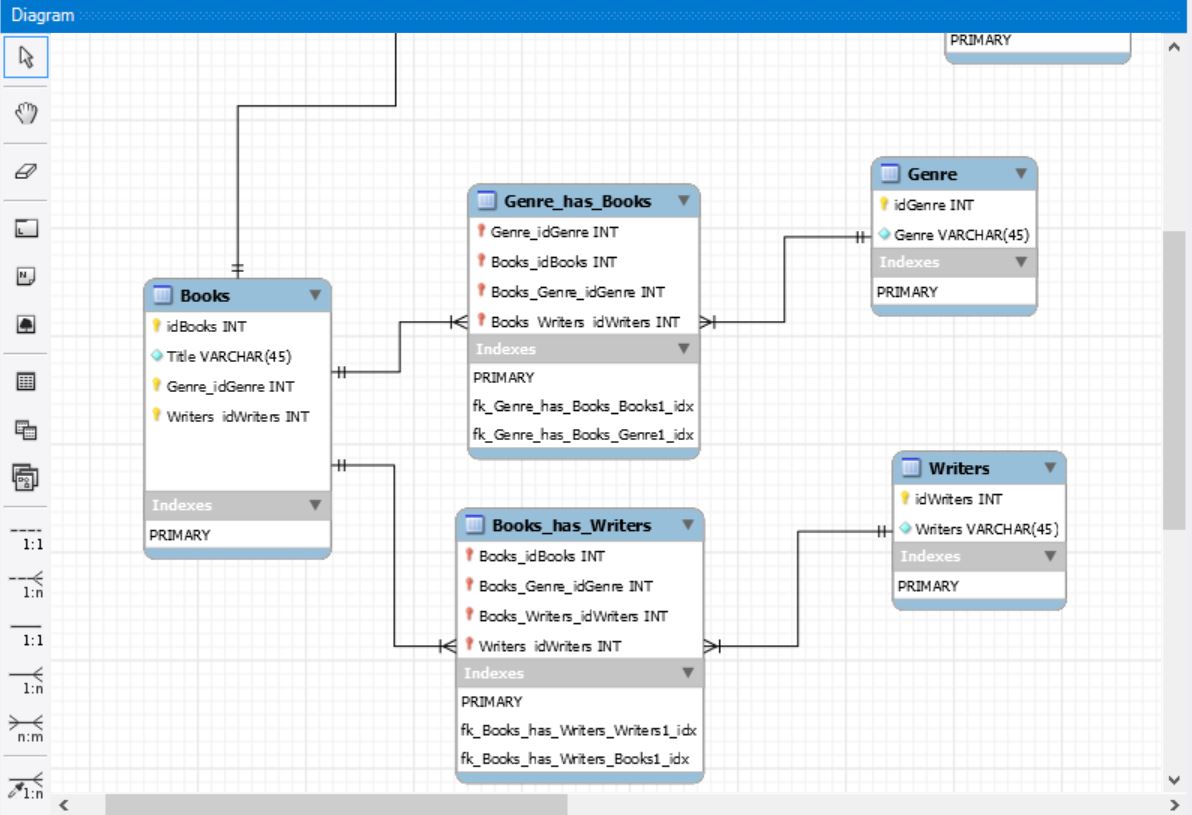
Ну и последний шаг – создаем физическую базу
DataBase > Forward Engeneer
Выбираем опции и настройки, которые нам нужны
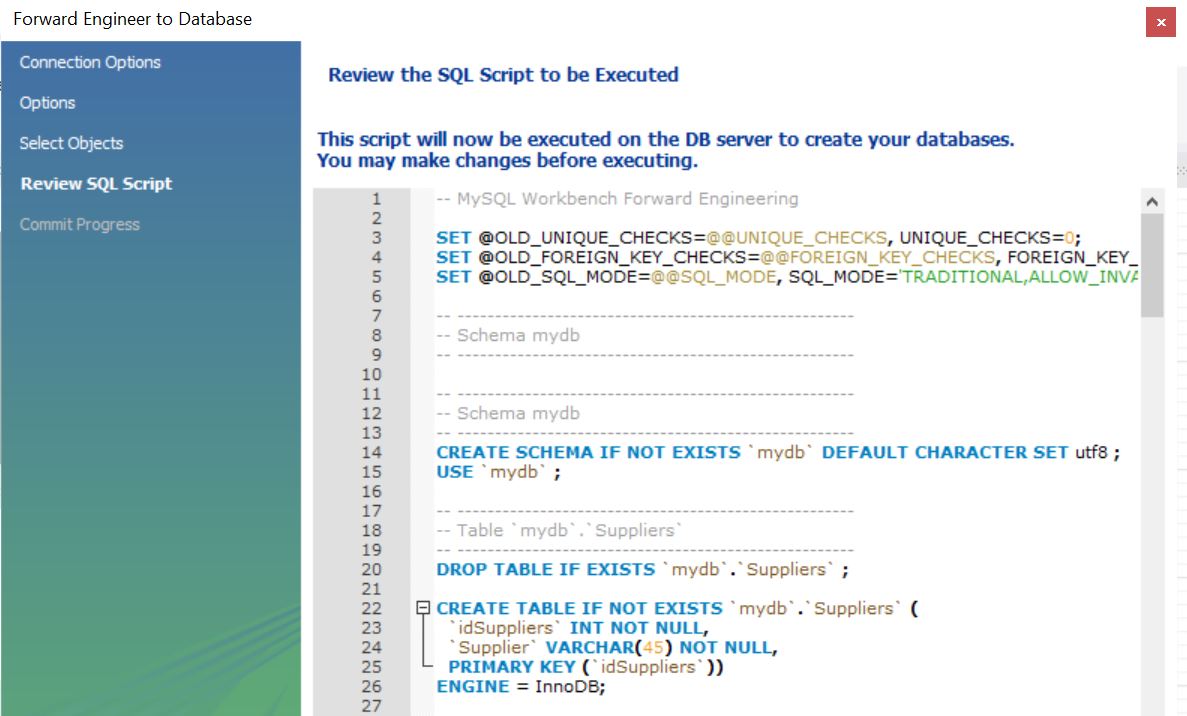
Далее собственно выполнение скрипта

Проверяем – создалась ли база и таблицы в реальной базе данных